Precision, accuracy and reliability
The precision of an estimator is usually evaluated by its variance. The bias on the other hand measures the accuracy of an estimator. A combined measure of precision and accuracy (variance and bias) is the mean squared error (MSE). A smaller MSE indicates that an estimate is more precise and/or accurate than a comparable estimate with a larger MSE. Every produced small area estimate should be accompanied with its MSE estimate. The MSE is defined by the expectation of the squared difference of the point estimate (mathjax-inline(\hat{\theta}_{i})mathjax-inline) and the true value (mathjax-inline(\theta_{i})mathjax-inline), at domain level (mathjax-inline(i)mathjax-inline) as follows
Since the true value is unknown, the MSE needs to be estimated. To estimate the MSE for model-based small area estimates, there exist different estimation methods:
- analytical,
- jackknife methods,
- bootstrap methods.
For direct estimates, the MSE equals its variance because direct estimates are assumed to be unbiased. Estimates for the MSE are commonly returned by software packages. For methodological derivations and the estimated components of the MSE, please refer to the standard SAE literature.
In order to have comparable evaluation criteria independent of the scale of the indicator, the coefficient of variation (CV) is often used to assess estimates' reliability. It is given by the ratio of the square root of the estimated MSE and the point estimate at domain
Often, the CV is expressed as a percentage by multiplying it by 100. Among statistical offices, the definition of sufficient reliability differs. The Office for National Statistics in the UK uses a top CV of 20% to define reliable estimates. The CV should be used with caution for ratios since the it could be high simply due to the fact that the point estimate is close to 0.
Benchmarking
Model-based small area estimates can differ substantially from their direct counterparts. This is especially true for areas with very small sample size. Thus, totalling the disaggregated small area estimates to a higher aggregation level likely leads to differences between the higher-level direct estimates and the aggregated small area estimates (from the lower levels). The differences can be even more severe if the model is wrongly specified. Consistent estimates are, however, essential to convince policy makers from the correctness and usefulness of lower-level estimates. For indicators such as the mean, totals or proportions, a solution to this issue can be benchmarking. The goal of benchmarking is to adjust the produced model-based estimates in order to achieve coherence between the aggregated model-based estimates and the higher-level direct estimates. A very simple but popular benchmarking approach is the ratio adjustment approach. As described in Rao and Molina (2015), it is used to ensure that the benchmarked small area estimates add up to a reliable direct estimate
with
, where (mathjax-inline(N_{i})mathjax-inline) and (mathjax-inline(N)mathjax-inline) are respectively the domain and population sizes,and
. The adjusted model based estimate of area
is given by multiplying each small area estimate
by a common adjustment factor,
While the ratio benchmarking is easy to estimate, it has the downsides that each model based estimator is adjusted by the same adjustment factor not taking into account the precision of the model-based estimates.
A benchmarking approach that can take the precision into account has been developed for area-level models by Datta et al. 2011. In this Bayesian approach, the benchmarked area-level estimator for domain is given by
where is equal to the population share of each area. Depending on the weight
, the formula allows for three different benchmarking options. 1) The weights used in the benchmarking, i.e.,
; 2) Setting the weights
creates a ratio adjusted benchmarked estimator that takes into account the size of the point estimate; 3) In the last option
, with (mathjax-inline(\bar{\hat{\theta}}_{\xi}^{EBLUP}= \sum_{i}^{D}\xi_{i}\hat{\theta}_{i}^{EBLUP})mathjax-inline), the benchmarking takes into account the precision. A detailed explanation of all three options is given in Datta et al. (2011).
There are also various other benchmarking methods for unit and area-level models, ranging from simple adjustment approaches, such as difference benchmarking to two-stage benchmarking and self-benchmarking (Rao and Molina 2015).
Practical exercise
The practical exercise in these guidelines will perform the analysis of three indicators for the SDGs 1, 7 and 8 with different input factors and estimation approaches. In this part, the evaluation and benchmarking of the produced estimators is described. The examples are chosen such that the application can be transferred to a wide range of SDG indicators.
Goal: For the proper planning of social support schemes, it could be of interest to target where the population below the national poverty line lives.
Indicator of interest: The proportion of the population living below the national poverty line. The proportion describes the fraction of the population with the characteristic of having, e.g., an income, below the poverty line and has a value between 0 and 1.
Disaggregation dimension: Required disaggregation dimensions for the indicator 1.2.1 are sex and age. However, the example only follows a spatial disaggregation by the second administrative level due to the common application of poverty mapping. The number of categories (domains) is 433 in the example.
To estimate the regional distribution of the proportion of the population living below a poverty line, the specification based on the input factors leads to the EBP. To implement the analysis, a software package needs to be chosen. For this example, the R packages emdi and maptools are used. Please note that the proportion of the population living below a poverty line is defined as the head count ratio (HCR) in the package emdi. Thus, the proportion will be named as HCR in the following.
The EBP approach is based on a linear mixed regression model that links the variable of interest, the equivalized income, with covariates and categorical predictors, e.g., age and working class. To use the categorical variables in a statistical model, they must be converted to factor variables in R. This lets the software know that it deals with categorical variables instead of numerical variables.
The aim of the next step is to fit a suitable model. In the example, two different models are being compared. The first model (povEBP_reduced) uses "age", "sex" and "yrschool" as independent variables, whereas the second model additionally uses the variable "classwkd" as independent variable. It is expected, based on theoretical knowledge, that these covariates are associated with the equivalized household income. The default option for the poverty line in package emdi is 60% of the median of the dependent variable which is a common definition in the European Union. However, adding an argument for the threshold allows to use any required poverty line.
With the help of the summary function, sample sizes in the sample and the census are displayed, as well as some model diagnostics, e.g., the (mathjax-inline(R^2)mathjax-inline) and the ICC. While there are multiple methods and criteria that can be used to compare different models, the (mathjax-inline(R^2)mathjax-inline) is used for this example. Based on the (mathjax-inline(R^2)mathjax-inline), the comparison shows that both models almost have an identical model goodness of fit. Because of the slight advantage of the full model over the reduced model it will be used going forward. The ICC indicates that there is unexplained heterogeneity between areas and the use of a random effects model is suitable.
After an appropriate model was chosen the model assumptions must be checked. As before the output of the summary function provides information about the residuals. When looking at the skewness and kurtosis, it is obvious that the normality assumption of the unit-level (Error) is not fulfilled in this example. The skewness of a normal distribution is 0 and its kurtosis is 3. The normality assumption can also be checked with statistical tests like the Shapiro-Wilk test. For the random effects, the test suggests that the hypothesis of normality is not rejected. However, the results are not returned for the unit-level error terms since the corresponding function in R is only defined for sample sizes between 3 and 5.000. If the test of the unit-level errors is of interest, another test like the Kolmogorov-Smirnov could be chosen.
Another option to check the normality is to use the plot function on the model object that returns different plots, e.g., a QQ-plot of the unit- and area-level residuals.
The plot underlines what the skewness and kurtosis estimates also indicate, namely that the normality assumption for the unit-level error is not fulfilled.

To stay within the same model class and to meet the normality assumption of the EBP method, the log and the data driven Box-Cox transformations are applied to the dependent variable of the model. As before, the summary and the plot functions are used to get information about the distribution of the residuals.
The estimated skewness and kurtosis of the residuals obtained from the newly fitted models (with log and Box-Cox transformations) indicate that the normality assumption of the EBP method might not be violated anymore. For both models, the skewness of the residuals is close to 0 and the kurtosis is close to 3 (as expected for the normal distribution).
Checking the QQ-plot of the newly fitted models' residuals confirms the prior findings. The next plot shows the results from the log model.

It is now up to the practitioner to decide if the model with either the log or the Box-Cox transformation should be used for producing the final estimates of the HCR, because both seem to fulfill the model assumptions quite well. In the next step, the final model (with log transformation) is fitted. The parameter L controls the number of Monte Carlo repetitions used in the EBP method. In the example, L is set to 100. Molina and Rao (2010) state that L=50 gives fairly accurate results but for practical applications they propose values larger than 200.
The estimated HCR per area can be printed in a table and plotted on a map. For the latter, a shape file needs to be available that contains the same regions for which the indicator is estimated for. Unfortunately, the shape file used in the example is too large to upload it such that it is not available for the user.
In the next figure, the produced map is plotted. Plotting the spatial distribution of the HCR enables policy makers to target political actions.

Evaluation & Benchmarking
To evaluate the domain indicators, the model is fitted and the MSE and the CV are estimated. The estimation of the MSE and CV is triggered by setting the parameter MSE to "TRUE". In emdi, the MSE and CV are estimated using bootstrap methods. The parameter B controls the number of bootstrap iterations. It is advisable to set B to a minimum value of 100 in order to obtain reliable MSE estimates.
The estimated regional indicators (the HCR in this example) with its MSE and CV can be obtained in the form of a table.
Additionally, the MSE and the CV can be plotted using the function map_plot. The results show that for some areas the estimated CV is considerably higher than 20% (threshold that is often used to argue that an estimator is reliable). This is a phenomenon often observed when working with ratio indicators. In the formula for the CV (given above), it is divided by the estimator (the estimated HCR). Hence, when the HCR takes on small values, the CV easily gets large.

To assess if the model-based HCR estimates are more reliable than the direct estimates various comparisons can be made. For sampled domains, the direct estimates and their CVs can be compared to the model-based estimates. Therefore, the direct estimates together with their variance are estimated. Afterwards, the CVs of the direct estimates are compared to the CVs of the model-based estimates.
The first plot shows a boxplot of the CVs of the HCR over the sampled areas for the model-based and direct estimates. The plot clearly indicates that the model based estimates are considerably more reliable than the direct estimates. Most of the model-based estimates have a CV of under 25%. The second plot presents the estimated CVs ordered by sample size (from large to small sample size). As expected, for large areas the estimated CV is comparable. With decreasing sample size the advantage of the model based method, in terms of lower CVs, is visible.


Additionally, the model-based estimated HCR can be compared to its direct counterpart. As expected, they are not identical but there is a strong linear relationship between them.

Before communicating the estimated indicators to policy makers, it can be desirable to benchmark the small area estimates to a direct national estimate. For estimating the direct national estimate, the whole sample is used. Afterwards, the popular but simple ratio adjustment method is applied to each model-based HCR estimate.
The results show that the benchmarked model based HCR estimates are all shrunk by the same factor of 0.88.
Evaluation & Benchmarking
To evaluate the domain indicators, the estimation is conducted and the MSE and the CV as measures for the uncertainty of the estimates are calculated. The estimation of the standard errors is automatically returned along with the point estimates. For the estimation of the CV, the function cv can be used. The CVs are far below the threshold of 20%. Thus, the direct estimation would be sufficient at this disaggregation dimension.
Benchmarking
Direct estimates have the property to sum up to the population estimate such that benchmarking is not necessary.
The goal of the analysis is to obtain estimates of the unemployment rate for different disaggregation dimensions. The following descriptions will be focused on the combination of the dimensions age group and geographic location.
To estimate the unemployment rate for the different disaggregation dimensions, the specification based on the input factors leads to direct estimation and an area-level model. To implement the analysis, a software package needs to be chosen. For this example, the R packages survey and emdi are used (for the data management, also package reshape2 is loaded).
The survey data set contains sampling weights to correct the differences in selection probabilities. One popular R package for the analysis of survey data, especially with complex survey designs, is the survey package. The survey design can be specified with function svydesign. In this example, the survey design is specified with the sampling weights.
The variable unemployment is 1, when the person is unemployed, and 0, when the person is employed. Thus, the unemployment rate can be directly estimated by taking the mean within the required disaggregation dimension. The function svyby enables the operation of function svymean for the estimation of the mean and its standard error by the required disaggregation dimension considering the sampling design.
For the combination of age groups in five year intervals and the geographic location, it is apparent that the unemployment rate is especially high for the young urban population with 14% in the age group 15-19.
While the direct estimation does not require any model building or checking, it is the starting point for the area-level model. The first set of inputs required for a basic area-level model are the direct estimates and their sampling error variances. While the sampling error variance is assumed to be known, it usually needs to be estimated from unit-level data (see Estimation of the sampling error variance for more information). In this application, the indicator of interest is a proportion defined between 0 and 1. Thus, it is recommended to use either a different model specification for variables between 0 and 1 or to use the arcsin transformation. The latter option is chosen since it allows to stay within the same model class. To apply the transformed area-level model, an approximation for the sampling error variance is needed. Thus, the effective sample size needs to be calculated. The design effect can be estimated with the svymean function from the survey package. The effective sample size is estimated by the division of the sample size and the design effect (Casas-Cordero, Encina e Lahiri, 2016).
The second set of inputs is the aggregated auxiliary information at the domain level. To use the package emdi for the analysis, the two data sets need to be combined into one. While the data preparation steps above can differ depending on the data set used, the data set that is given to the function fh in the package emdi needs to look like the combined data set below, containing the direct estimate, the sampling error variance (here estimated by the direct variance), the effective sample size (if the arcsin transformation is applied), and the auxiliary variables.
The aim of the next step is to fit a suitable model. The auxiliary data has information of working class and educational attainment. Both categorical predictors are potentially associated with employment status. Thus, two models are built and compared. For fitting the model, the R package emdi is used since it provides the option of using the arcsin transformation. The bias-corrected backtransformation is chosen (bc) instead of a naive backtransformation.
With the help of the summary function, the practitioner gets information about the number of domains as well as some model diagnostics, e.g., the information criteria and the (mathjax-inline(R^2)mathjax-inline). While there are multiple methods and criteria that can be used to compare different models; in this example, the focus is on the information criteria and the adjusted (mathjax-inline(R^2)mathjax-inline). Since the information criteria AIC and BIC are smaller in unemplFH2 and the adjusted (mathjax-inline(R^2)mathjax-inline) is larger for this model, it will be used going forward. Please note that the estimation method for the parameters needs to be set to maximum likelihood if the information criteria will be used for the model selection.
After an appropriate model is chosen the model assumptions must be checked. As before the summary function provides information about the residuals and the random effects. When looking at the skewness and kurtosis, it seems that the kurtosis estimates for the distribution of the residuals and random effects are compatible with a a normal distribution but that the data is slightly skewed. The skewness of a normal distribution is 0 and its kurtosis is 3. The Shapiro-Wilk test that tests the hypothesis whether the data follows normal distribution does not reject the normality of the residuals and random effects. Another option to check the normality assumption can be various plots, e.g., a QQ plot that can be produced with the plot function.
The QQ plots show a difficulty of this application. The area-level model is conducted with only 22 domains in this example. With a small number of domains, it is more likely that the Shapiro-Wilk test will not reject the normality (the null hypotheses). The QQ plots may help to confirm or to reject the normality assumption. However, it is also up for interpretation. For the following, the model unemplFH2 is used as a final model assuming no violation of the model assumptions.

After checking the model, the final model can be fitted. The estimators function returns a table that allows a fast comparison of the model-based estimates with the direct estimates. For the final model, the default estimation which is restricted maximum likelihood is used in this example.
The returned table of point estimates shows that the estimates are quite similar for the domains.
Evaluation & Benchmarking
To evaluate the domain indicators, the model is fitted and the MSE and the CV as measure for the uncertainty of the estimates are calculated. The estimation of the MSE and CV is triggered by setting the parameter MSE to "TRUE". For the transformed area-level model with bias-corrected backtransformation, a bootstrap MSE is provided. The parameter B controls the number of bootstrap iterations. It is advisable to set B to a minimum value of 100 to obtain reliable MSE estimates.
The estimated regional indicators (the unemployment rate in this example) with its MSE and CV can be obtained in the form of a table. Generally, the CV should be used with caution when the indicator of interest is a ratio since point estimates close to zero can also be the reason for large CVs. In these cases, it is recommendable to focus on the MSE.
In this example, the CV of the model-based estimate (FH) is generally lower than for the direct estimate. However, there are also cases where the CV is slightly larger. One reason could be that the number of bootstrap iterations is too small.
The model-based estimates are commonly compared with the results of direct estimates. The function compare_plot in emdi provides some plots for this comparison.
Comparing direct with model-based estimates helps to evaluate if the model-based estimates are more reliable than the direct estimates measured in terms of the MSE or the CV. The boxplots confirm that the model-based estimates have lower CVs overall. Approximately, 75% of the model-based domain estimates show a CV below 20%. It is also apparent that the increase in efficiency is not huge. Furthermore, the second plot (on the right) shows that there are also domains where the CV of the model-based estimates is slightly larger than those of corresponding direct estimates.


When comparing the direct and model-based point estimates, it can be seen that these do not differ strongly from each other.

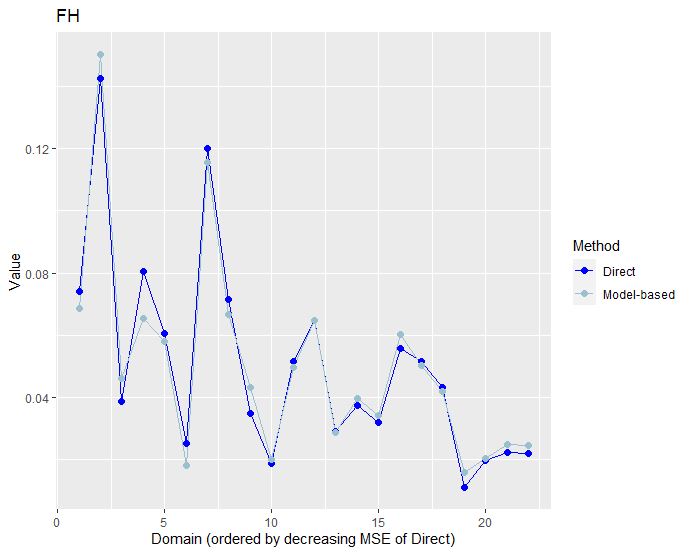
This could be due to a large weight on the direct estimator. For this, the estimated shrinkage factor can be checked. Furthermore, the Brown test can be conducted and the correlation between the direct estimates and the estimates of the regression-synthetic part can be calculated with the function compare.
The results show that the weight on the direct estimate ranges between 0.3 and 0.75 with a median of 0.6. Thus, the weight on the direct estimate is relatively high. Furthermore, the hypothesis that the model-based estimates differ from the direct estimates is not rejected and the correlation between the direct estimates and the regression-synthetic part is high with 0.93.
Before communicating the estimated indicators to policy makers, it is common practice to to benchmark the small area estimates to a direct population estimate. For estimating the direct population estimate, the whole sample is used. In this example, the aggregation of the model-based domain estimates is about 5.5%, already quite close to the direct population estimate of 5.6%. This is due to the fact that the model-based domain estimates are close to the direct domain estimates. To ensure the direct population estimate, the benchmarking following Datta et al. (2011) (option 1) is used in this example. To conduct the benchmarking the population shares per domain are needed.
The benchmarking changes the estimates only slightly.
No interpretation of results
Please note that none of the results can be interpreted in any way. The data provided is solely used to explain the methods and how to conduct a study, and are not meant for a real analysis.